TextRAG — 사내 RAG 시스템
사내 자료를 외부 LLM에 못 보내는 제약과 좁은 RAM(3모델 동시 상주 불가)을, 인덱싱·서빙 장비 분리와 메모리 예산 설계로 푼 로컬 RAG — 혼자 만들어 운영 중, recall@5 87%
언어
- Python3
- Shell
기술
- FastAPI
- Ollama
- vLLM
환경
- PyCharm
- VSCode
외부 LLM에 사내 자료를 보낼 수 없는 환경에서, 로컬 LLM과 자체 임베딩으로 구성한 사내 RAG 시스템(TextRAG)을 설계하고 도입부터 운영까지 맡고 있습니다.
배경·과제
-
취미로 만들던 로컬 RAG 도구를, 노션·컨플루언스·지라에 흩어진 사내 자료와 이슈 히스토리를 빠르게 찾기 위해 사내 인프라로 옮기고 확장했습니다.
-
보안 제품을 만드는 회사 특성상 외부 LLM API를 쓸 수 없어, 사내 전용 검색·생성 인프라가 필요했습니다.
-
서빙 장비의 RAM이 작아 임베딩·재정렬·생성 모델을 동시에 띄울 수 없는 제약이 있었습니다.
수행·기여
-
노션·컨플루언스·지라 자료를 한 곳에서 자연어로 검색하고, 질문 의도에 맞는 문서만 추렸습니다.
-
문서 유사도로 비슷한 자료를 찾고, 코퍼스 단위로 묶어 검색 범위를 지정할 수 있게 했습니다.
-
Claude Code 등 개발 도구와 MCP로 연결해 코드 맥락과 이슈 히스토리를 가져와 코드 작성과 기획 문서 작성 때 활용했습니다.
-
구글 계정 로그인 기반 접근 제어를 붙여, 그룹별로 매칭된 코퍼스만 검색할 수 있도록 했습니다.
-
인덱싱 전용 장비와 서빙 전용 장비로 분리해 3단 모델 스택을 운용했습니다.
-
모델별 keep_alive 토글, 재정렬 선택 비활성, KV cache 축소로 메모리 예산을 짜서 동시 상주 문제를 풀었습니다.
-
코드를 심볼 청크와 패시지 청크로 나눠, 코드 검색과 서술형 답변 양쪽에 재사용했습니다.
-
검색 기능을 Claude Code MCP 도구로 공개하고, 설치 스크립트와 가이드를 만들어 iOS 팀 교육을 진행했습니다.
-
코드 리뷰용 API 엔드포인트를 열어 GitLab MR 리뷰봇이 같은 엔진을 쓰도록 했습니다.
-
검색·답변 1건마다 지연·결과 수·점수·호출원을 비침습 방식으로 기록하는 계측 레이어를 붙였습니다. 검색 파이프라인은 그대로 두고 쿼리는 해시만 남겨, 로깅이 실패해도 서비스가 멈추지 않게 했습니다.
-
대표 질의 30문항 골든셋과 회귀 스크립트로 recall@k, MRR, 혼입률을 계산하고 기준선 대비 회귀를 비교했습니다.
성과
-
사내 문서 수천 건과 여러 제품 코드베이스를 색인한 상태로 상시 운영하고 있습니다.
-
단일 서버 엔진을 사내 검색·MCP 도구·MR 리뷰봇이 함께 쓰는 공통 인프라로 만들었습니다.
-
골든셋 30문항으로 검색 품질을 측정했습니다. recall@5 87%, MRR 0.76, 코드 검색은 거의 100%였습니다. 약한 구간의 원인을 확인해 개선 방향을 잡았습니다.
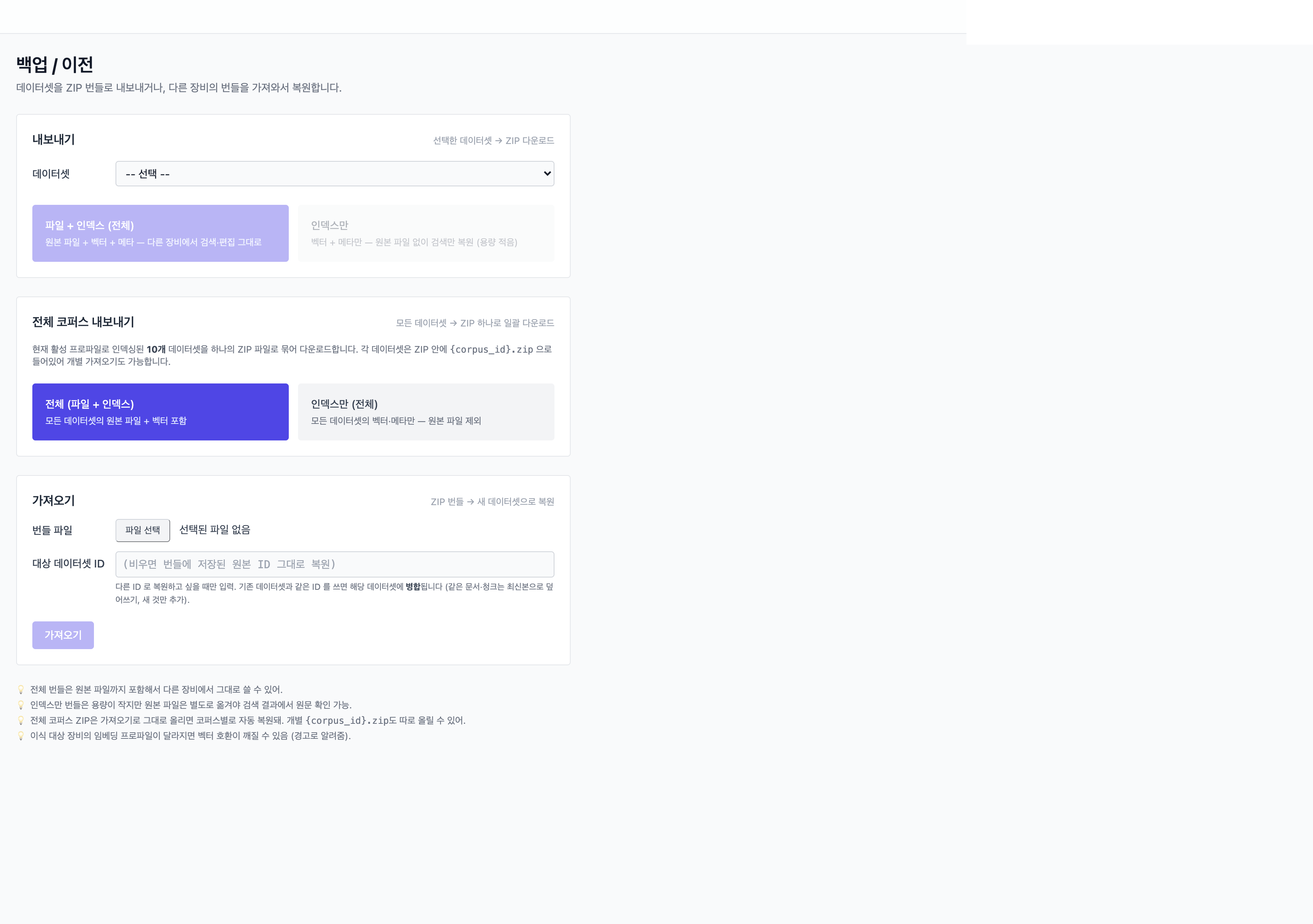
화면
-
평가 측정 과정의 허점을 두 가지 찾아 수정해, 수치를 신뢰할 수 있게 했습니다.
-
검색 사용량·속도·실패율을 자동 수집해 운영 상태를 꾸준히 점검합니다.
-
제안부터 설계, 구현, 서버 구축, 배포, 도입 교육까지 한사이클로 직접 진행했습니다.